随着AI翻译和机器翻译工具越来越普及,很多作者在论文写作过程中,可能会想,如果把外文文献通过机器翻译后,再整理成英文内容,CrossCheck还能检测出来吗?尤其是在国际论文投稿中,一些作者会认为。,只要经过翻译,语言已经变了,查重系统应该识别不了。近年来,随着CrossCheck以及iThenticate底层算法不断升级,系统对于翻译型重复的识别能力,已经比很多人想象中更强。虽然它不像传统复制粘贴那样直接匹配文字,但经过机器翻译后的内容,依然有可能与原始文献形成相似性关联。
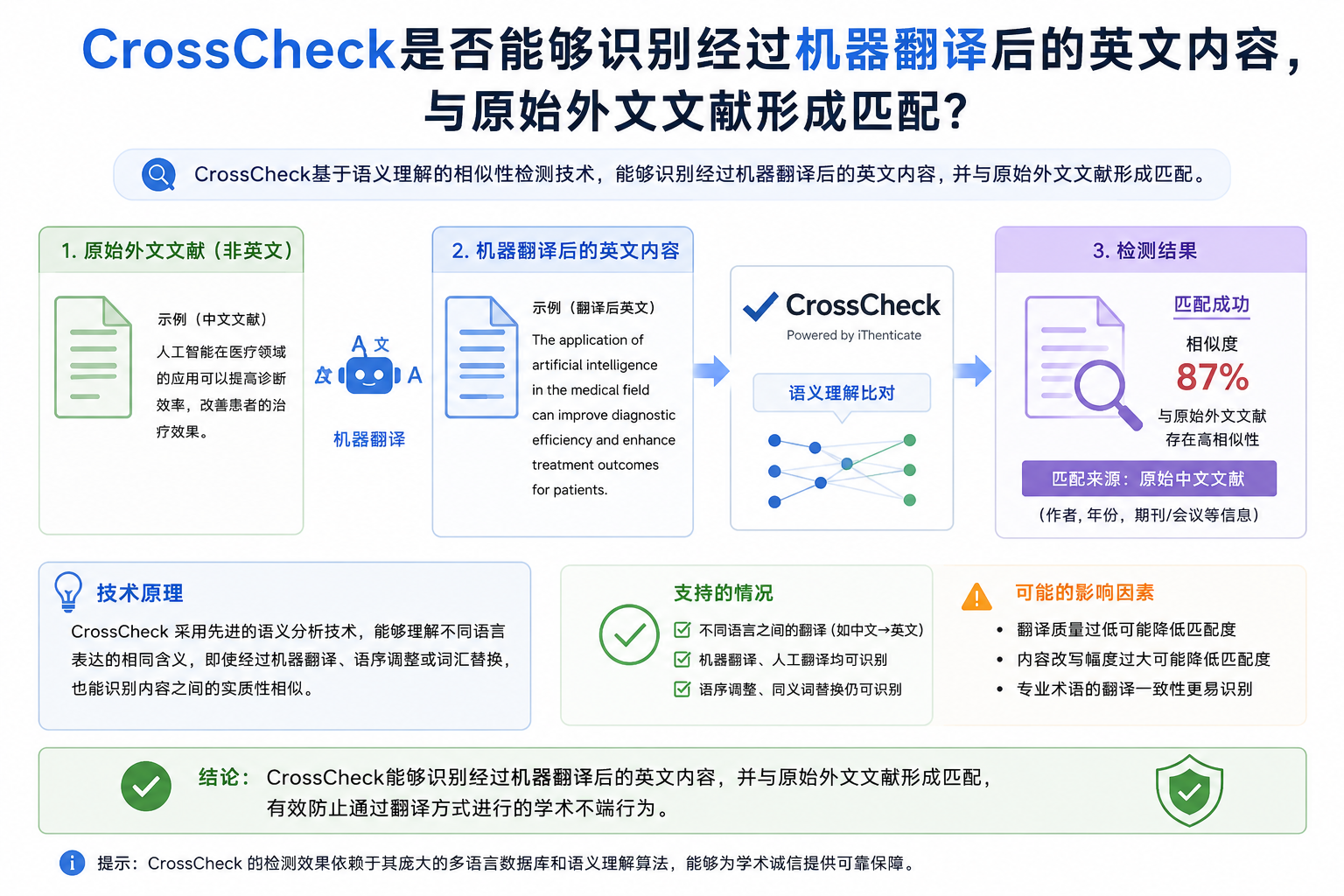
CrossCheck本质上查的是什么?
很多人容易误以为,CrossCheck只是逐字对比,其实并不完全如此。CrossCheck(基于iThenticate技术)最核心的能力,确实是文本匹配,但它并不仅仅依赖完全相同的单词。
系统在比对时,还会关注:
- 句子结构;
- 连续表达逻辑;
- 术语排列方式;
- 长文本相似片段;
- 特征性学术表达。
因此,即使文字经过翻译,只要整体表达路径高度接近,系统依然有可能识别出相似性。尤其是在学术论文这种结构化写作场景中,很多内容即使翻译后,也很难真正脱离原文逻辑。
机器翻译为什么容易留下相似痕迹?
因为机器翻译的本质,是语言转换,而不是内容重构,很多翻译工具虽然改变了语言,但往往会保留:
- 原句顺序;
- 原有逻辑结构;
- 学术术语组合;
- 句式关系;
- 段落组织方式。
例如:
原文如何提出问题,如何解释实验,如何展开论证等,翻译后通常仍然沿用相同逻辑,这就意味着,即使单词发生变化,文章的表达骨架依然可能高度相似。而这类相似性,恰恰是CrossCheck越来越关注的部分。
英文翻译英文,风险其实更高
很多作者会觉得,中文翻译成英文,系统可能识别不到。但实际上,如果是,英文原文 → 机器改写 → 新英文文本,这种情况往往更容易形成匹配,因为语言本身没有变化,系统会更容易识别:
- 同义替换;
- 句式微调;
- 词汇替换;
- 语序调整。
尤其是一些伪改写内容,即只替换少量词汇,但整体结构完全一致,这种情况在CrossCheck中,通常比跨语言翻译更容易暴露。
跨语言翻译,系统还能识别吗?
严格来说,目前传统CrossCheck并不是专门的跨语言查重系统,它不像某些AI语义模型那样,直接进行深层跨语言语义对比。因此,中文直接翻译成英文后,未必一定会像原文复制那样形成高重复率,但这并不意味着完全安全。因为现实中,很多翻译内容仍会暴露明显特征。
例如:
- 专业术语高度一致;
- 论证顺序完全相同;
- 数据解释路径一致;
- 段落结构高度对应;
- 特色表达被保留。
再加上近年来AI检测和编辑人工审核越来越严格,即使系统本身没有直接标红,编辑也可能通过人工阅读发现问题。尤其是高水平SCI期刊,对这种翻译式改写其实非常敏感。
为什么方法学部分最容易出现翻译重复?
在实际查重中,Methods部分一直是高风险区域,因为:
- 方法描述本身标准化;
- 专业术语固定;
- 实验步骤逻辑稳定;
- 表达空间有限。
很多作者会把外文论文的方法部分直接翻译后使用。但问题在于,即使语言变化,实验逻辑和步骤顺序往往完全一致。因此,这类内容特别容易形成,低文本重复,高结构相似。对于经验丰富的编辑来说,这种痕迹其实并不难识别。
AI翻译工具会降低查重风险吗?
近年来,不少人开始使用:DeepL、ChatGPT、Google Translate和AI改写等工具,希望通过智能改写降低重复率。从技术角度来说,这类工具确实可能降低传统文本匹配比例。因为它们会,替换表达,调整句式以及改写语法结构。但问题在于,真正的学术查重,越来越不只是查词。很多国际期刊现在更关注,内容来源,研究逻辑,表达原创性,是否存在隐性改写等,因此,即使重复率下降,也不代表学术风险完全消失。尤其是在同行评审阶段,专业审稿人往往比系统更容易发现,这段内容像是从某篇经典论文翻译过来的。
编辑如何看待翻译型重复?
这一点其实非常关键,很多作者误以为,只要查重率不高,就没问题。但实际上,在国际出版伦理中,未经规范引用的翻译性使用,同样可能被视为不当借鉴。因为本质上,思想表达和论证结构依然来源于原文。特别是以下情况,大段翻译他人论文,保留原有论证逻辑,未进行规范引用,仅做语言转换等。即使系统没有形成高重复,编辑依然可能认定存在学术伦理问题,因此,CrossCheck只是第一层筛查,真正的判断,往往来自编辑和审稿人的人工审核。
为什么有些翻译内容查重率并不高?
目前大多数传统查重系统,核心仍然是文本匹配,如果跨语言转换幅度较大,系统可能无法像原文复制那样直接识别,尤其是:
- 中文与英文之间;
- 日文与英文之间;
- 多次改写后的内容;
文本重合率可能明显下降。但需要注意的是,查不出来不等于没有问题。很多高水平期刊越来越重视:
- 学术表达真实性;
- 原创研究能力;
- 是否存在隐性借鉴。
因此,仅靠翻译规避查重,本身就是一种高风险行为。
如何正确使用外文文献?
比较规范的做法应该是,理解原文内容后,用自己的研究逻辑重新组织表达。而不是,直接翻译原句,再进行机械改写,尤其是引言,文献综述和讨论部分,更应该体现作者自己的理解与分析,即使引用外文观点,也应该明确标注来源,进行合理归纳,避免整段结构照搬。这才是真正符合国际学术规范的写法。
CrossCheck虽然本质上仍属于文本相似性检测系统,但随着算法和编辑审核机制不断升级,对于机器翻译后的内容,已经具备越来越强的识别能力,尤其是在学术论文这种结构化文本中,即使语言发生变化,论证逻辑、句式结构和专业表达依然可能暴露相似痕迹。因此,机器翻译并不等于真正意义上的原创写作,对于国际期刊来说,真正重要的也从来不只是重复率数字,而是论文是否具备独立、规范、真实的学术表达能力。



