很多作者在使用Crossref查重时,可能会遇到这样的情况,同一篇论文,可能同时出现在多个平台上。例如:
- 期刊官网
- 数据库平台
- 学校机构库
- ResearchGate
- 预印本平台
- 第三方全文网站
这时候,很多作者会担心一个问题,如果同一篇文章被多个网站同时收录,Crossref查重会不会把这些来源全部重复计算,从而导致重复率偏高?
这个问题其实非常典型,也是很多作者第一次接触国际查重系统时容易产生的误区。
因为从查重报告上看,确实经常会出现一段内容对应多个来源的情况,看起来似乎像是被重复统计了很多次。但实际机制,并不是简单的来源越多,重复率越高。
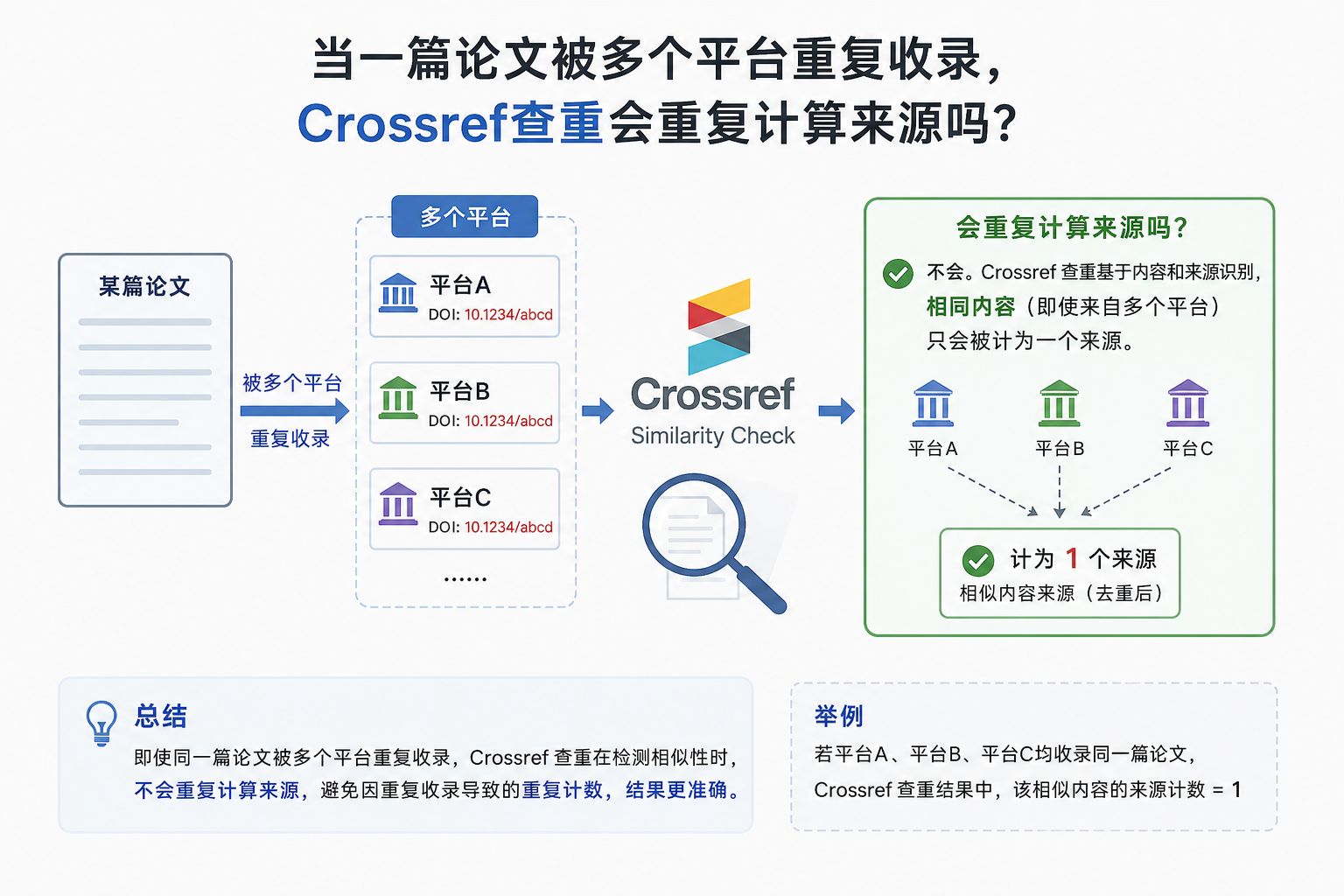
Crossref查重是如何识别重复来源的?
首先要明确一点,Crossref Similarity Check本质上使用的是iThenticate的比对技术。它的核心逻辑,并不是单纯统计来源数量,而是识别文本相似内容。也就是说:
系统真正计算的,是重复文本覆盖范围,而不是出现了多少个平台,很多作者会误以为,同一段文字如果同时出现在5个网站,就会被算5次重复。实际上,正常情况下并不会这样。
为什么查重报告里会出现多个相同来源?
这是因为同一篇论文可能已经被多个数据库同步收录。例如:
一篇SCI论文发表后,可能同时出现在:
- 出版社官网
- Crossref数据库
- 学术搜索平台
- 图书馆镜像数据库
- 学术社交网站
系统在比对时,会识别到这些不同来源中存在相同文本,因此报告里可能同时列出多个匹配来源。但这里需要区分两个概念:显示多个来源和重复计算重复率并不是一回事。
正常情况下,系统不会简单叠加重复率
这是很多人最关心的问题。举个简单例子。假设论文中有一段100词内容,与某篇已发表论文完全一致。而这篇已发表论文同时存在于:
- A数据库
- B平台
- C网站
那么查重报告里,可能会显示3个来源,但系统通常不会把这100词算成300词重复,因为这些来源本质上对应的是同一段文本。Crossref/iThenticate的算法,一般会进行来源聚合(source consolidation)或重叠处理,重复内容主要按文本区域统计,而不是按来源数量无限累加。所以,大多数情况下,并不会因为同一论文被多个平台收录,就导致重复率成倍增加。
为什么有时候看起来重复率变高了?
虽然系统不会简单重复累加,但实际检测中,确实可能出现一种情况,多个来源导致匹配区域扩大。例如:
- A平台收录的是摘要;
- B平台收录的是全文;
- C平台收录的是补充材料;
- D平台收录的是会议版本。
这些来源之间可能存在部分差异,系统在比对时,会从不同来源中识别出更多重叠文本区域,这样一来,最终整体重复覆盖范围可能变大。所以,作者会感觉,为什么来源越多,重复率似乎越高了?实际上,并不是同一内容被重复计算,而是不同平台提供了更多可匹配文本。
预印本与正式发表版本尤其容易出现这种情况
这是近年来特别常见的问题,很多作者会先上传:
- arXiv
- bioRxiv
- SSRN
- Research Square
之后再正式投稿期刊。正式发表后,系统中就可能同时存在:
- 预印本版本
- Accepted Manuscript
- 正式出版版本
- 数据库转载版本
由于这些文本高度相似,查重报告中往往会出现多个来源。但一般来说,编辑能够识别这些属于同一论文链条。因此,只要属于作者自己的合法公开版本,通常不会被简单认定为学术不端。不过,如果作者没有提前说明,或者期刊本身对预印本政策较严格,仍然可能引起编辑关注。
编辑真正关注的是什么?
实际上,在Crossref查重中,经验丰富的编辑并不会只看来源数量。他们更关注的是:
- 重复内容是否属于同一篇文章;
- 是否存在一稿多投;
- 是否涉及重复发表;
- 是否属于作者本人已发表内容;
- 是否存在未说明的自我重复。
换句话说,多个来源本身并不可怕。真正关键的是,这些来源之间的学术关系是什么。例如:
如果多个来源都指向同一篇已发表论文,那么编辑通常能识别这是同源重复。但如果多个来源来自不同论文、不同作者、不同平台,那么问题性质就完全不同了。
为什么有时候报告会显示Primary Source?
很多作者在iThenticate或Crossref查重报告中,会看到一个Primary Source(主要来源)。这是因为系统通常会自动选择:最完整、最权威、最早或最相关的来源,作为核心匹配来源。其它重复来源则可能被归类为:
- secondary matches
- overlapping sources
- similar sources
这种机制,本质上也是为了避免重复统计。因此,看到多个来源,并不意味着系统一定进行了重复累加。
自己发表过的论文会不会因此重复翻倍?
这是很多SCI作者最担心的问题。实际上,如果作者之前发表的文章被多个数据库同步收录,那么新的投稿确实可能匹配到很多来源。但正常情况下:
系统不会因为同一论文出现在多个网站,就机械性重复增加相似度。不过,如果作者在新论文中大量复用旧内容,即使来源本质相同,依然可能形成较高的自我重复率。尤其是:
- 引言
- 方法学
- 数据描述
- 讨论部分
这些区域最容易出现问题。因此,真正需要关注的,并不是平台数量,而是文本复用程度。
如何正确理解Crossref中的多来源匹配?
比较准确的理解方式是:Crossref查重中的多个来源,更像是多个证据入口,而不是重复叠加计数器。系统会展示这些相似内容在什么地方出现过,但最终重复率,主要还是基于文本重合区域进行计算。所以,大多数情况下:同一篇论文被多个平台收录,并不会导致重复率无限放大。真正影响结果的,仍然是论文本身的文本重复范围。
在Crossref查重体系中,同一篇论文被多个平台收录,是一种非常常见的现象。查重报告中出现多个相似来源,也并不意味着系统一定进行了重复累计。正常情况下,iThenticate会对重叠来源进行一定程度的合并与识别,避免简单重复计算。不过,如果不同平台提供了更多可匹配文本,或者作者本身存在较大范围的内容复用,那么整体重复区域仍然可能扩大。因此,对于作者来说,真正需要关注的,始终不是来源数量,而是论文内容本身是否具备合理、规范的原创表达。



